Meta 的 SeamlessM4T AI 模型可将语音、文本翻译成 100 种语言
Meta 希望使计算机视觉公平性的基准测试变得更容易。
Meta 正在扩展其开源计算机视觉工作,以鼓励开发更负责任的系统。SeamlessM4T,一种新的多模式人工智能模型,可以将音频翻译成文本以及将文本翻译成语音。
Facebook 母公司宣布将Modulate 的人工智能语音聊天审核工具Modulate 的人工智能语音聊天审核工具
自动语音识别
语音到文本翻译
语音到语音翻译
文本到文本翻译
文本到语音翻译
DINOv2 是一系列用于编码视觉特征的基础模型。它使用自我监督,可以从任何图像集合中学习 - 包括图像的深度估计。
该团队计划探索 SeamlessM4T 如何发展以“实现新的通信功能——最终使我们更接近一个每个人都能被理解的世界。
如何访问SeamlessM4T
《使命召唤》已经聘请了一个反毒团队,其中包括针对游戏内文本(如聊天和用户名)的 14 种语言基于文本的过滤。CC BY-NC 4.0 许可证。该公司希望研究人员和开发人员“以这项工作为基础”。
DINOv2 演示可以在此处访问 -
Meta还推出了评估计算机视觉模型公平性的新基准——FACET(这里 irness in Vision Evalua T ion)。
如何尝试 SeamlessM4T
Meta 的人工智能团队表示,计算机视觉公平性的基准测试传统上“很难做到”。
Meta 在博客文章中表示:“贴错标签的风险是真实存在的,使用这些人工智能系统的人可能会获得更好或更差的体验,这不是基于任务本身的复杂性,而是基于他们的人口统计数据。”https://seamless.metademolab.com/
FACET 纯粹用于研究评估目的。它不能用于训练商业人工智能模型。
相关:人工智能音频生成:您需要了解的一切
1 - 用您选择的语言录制一个完整的句子。
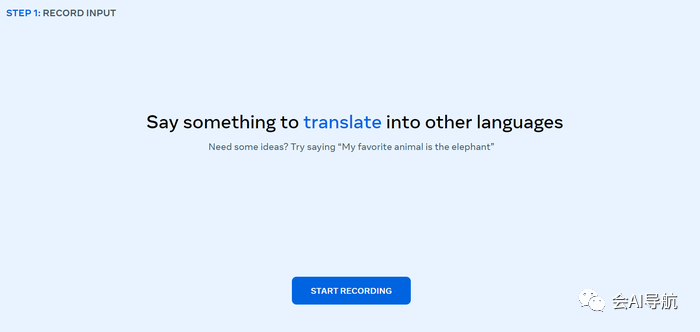
2 - 最多选择三种语言来翻译句子。

3 - 查看转录并聆听翻译。
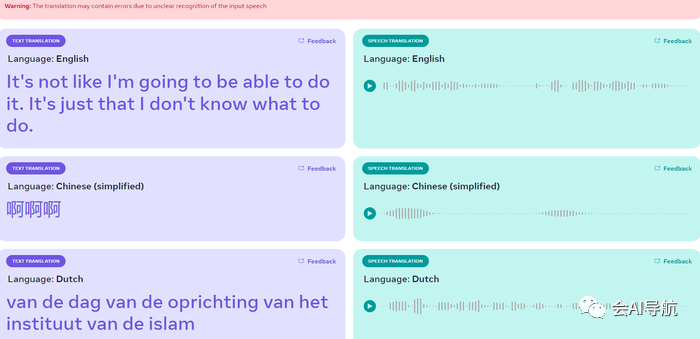
然而,该演示并非没有缺陷,Meta 指出它可能会生成不准确的翻译或改变您所说的单词的含义。正如您在上面所看到的,当输入谈论视频游戏“我们之中”时,结果有很大不同——从用英语谈论喇叭到用荷兰语谈论阿联酋的形成。
其研究人员发现,在感知性别表现方面, DINOv2 的表现比 OpenCLIP(OpenAI https://huggingface.co/spaces/facebook/seamless_m4t的网络爬虫版本)差。
然而,在感知年龄组和肤色方面,DINOv2 的表现优于 OpenCLIP 和 Meta 自己的 SEERv2 模型。
通过 Hugging Face 演示,用户可以将音频文件放入模型中进行翻译,甚至通过设备的麦克风录制新的输入。
技术讲座:SeamlessM4T 如何工作?
Meta 表示,FACT 使其能够通过“在类别层面更深入地研究模型的潜在偏差”来解决未来潜在的缺陷。公告称,Meta 的人工智能研究人员探索了构建类似于《银河系漫游指南》中的巴别鱼的通用语言翻译器的可能性。
Meta 的研究人员认为,实现这一目标的挑战在于,语音转语音和语音转文本系统“只覆盖了世界语言的一小部分”,并补充说,由于此类模型利用大量数据,因此通常表现良好仅针对一种模式。
相关:元开源文本到音频和音乐模型
为了构建 SeamlessM4T,Meta 的 AI 研究人员采用了Fairseq(其序列建模工具包),并使用更高效的建模和数据加载器 API 重新设计了它。
对于模型,Meta 使用多任务 UnitY 模型架构,能够直接生成翻译文本和语音。UnityY 支持自动语音识别、文本到文本、文本到语音、语音到文本和语音到语音翻译,这些已经是常规 UnityY 模型的一部分。
多任务 UnitY 模型由三个主要的顺序组件组成。Meta 表示:“文本和语音编码器的任务是识别近 100 种语言的语音输入。然后,文本解码器将该含义转换为近 100 种文本语言,然后使用文本到单元模型将其解码为 36 种语音语言的离散声学单元。
“对自监督编码器、语音到文本、文本到文本翻译组件和文本到单元模型进行预训练,以提高模型的质量和训练稳定性。然后将解码的离散单元转换为使用多语言 HiFi-GAN 单元声码器转化为语音。”
相关:Meta 开发人工智能聊天机器人:从 Abe Lincoln 到 Surfer Dude
该模型的自监督语音编码器 w2v-BERT 2.0 是w2v-BERT的改进版本,通过分析数百万小时的多语言语音来发现语音的结构和含义。
然后,编码器获取音频信号,将其分解为更小的部分,并构建所说内容的内部表示。然后 Meta 应用长度适配器来映射单词。
SeamlessM4T 还包含一个基于 Meta 的NLLB(无语言落后)模型的文本编码器。该文本编码器经过训练,可以理解近 100 种语言的文本。
在用于训练 SeamlessM4T 的其他工具中,Meta 创建了一个称为句子级模态和语言无关表示(SONAR) 的文本嵌入空间。
SONAR 可以支持多达 200 种语言,可用于自动对齐超过 443,000 小时的语音与文本,并创建约 29,000 小时的语音到语音对齐。
结合其新的 SeamlessAlign 数据集,Meta 的研究人员声称创建了“迄今为止就总容量和语言覆盖范围而言最大的开放语音/语音和语音/文本并行语料库”。
SeamlessM4T 的表现如何?
据 Meta 称,SeamlessM4T 已在近 100 种语言上取得了成果。
为了测试该系统,研究人员将该模型应用于 BLASER 2.0 评估,发现该模型在语音转文本任务中针对背景噪声和说话者变化的表现更好,平均改进分别为 37% 和 48%。
SeamlessM4T 被发现优于 AI 模型,包括 OpenAI 的 Whisper v2 和 Google 的 AudioPaLM-2。
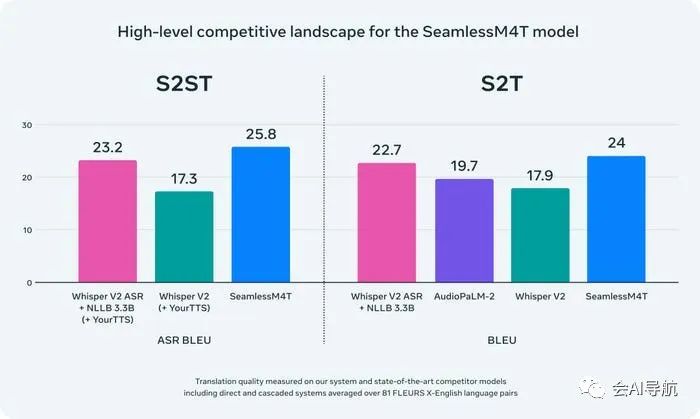
完整的结果可以在SeamlessM4T 论文中找到。
滥用的可能性如何?
Meta 的团队在推出 SeamlessM4T 时承认,与大多数人工智能系统一样,它存在可能被用于有毒目的的风险。
在构建 SeamlessM4T 时,Meta 使用多语言毒性分类器从语音输入和输出中识别出潜在的有毒单词。然后从训练数据中过滤掉不平衡的毒性。
Meta 表示,它可以检测 SeamlessM4T 演示的输入和输出中的毒性,并补充道:“如果仅在输出中检测到毒性,则意味着添加了毒性。在这种情况下,我们会添加警告并且不显示输出。”
背后的团队表示,他们还能够通过将之前设计的多语言整体偏差数据集扩展到语音来量化语音翻译方向中的性别偏见。
Meta 承诺继续研究语音识别中的毒性并采取行动,并计划不断改进 SeamlessM4T 并减少模型中的任何毒性实例。
想要了解更多AI工具的小伙伴也可以加入我们的群~
我们的导航站-会AI导航,目前收录了超过500+款热门AI工具,也是全网首个接入GPT助手的导航站